 |
|
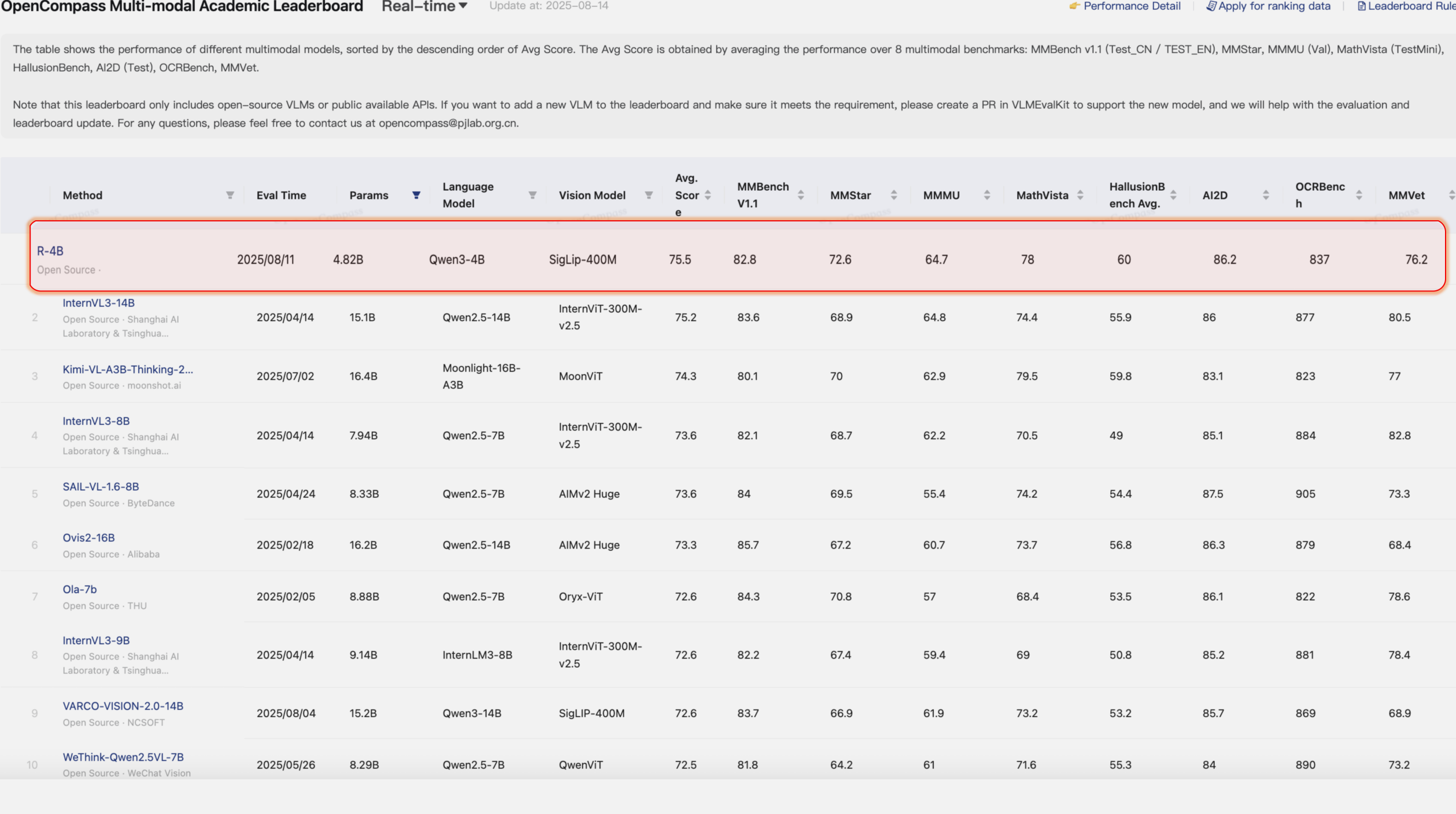
R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
Qi Yang,
Bolin Ni,
Shiming Xiang,
Han Hu,
Houwen Peng,
Jie Jiang
|
|
|
 |
|
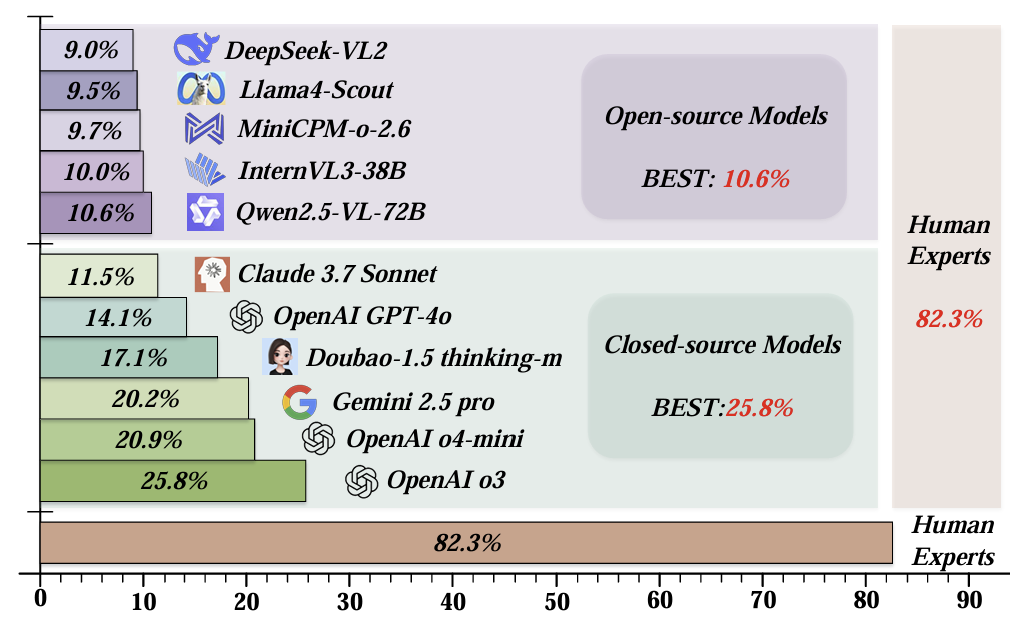
R-BenchV: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
Meng-Hao Guo,
Xuanyu Chu,
Qianrui Yang,
Zhe-Han Mo,
Yiqing Shen,
Pei-lin Li,
Xinjie Lin,
Jinnian Zhang,
Xin-Sheng Chen,
Yi Zhang,
Kiyohiro Nakayama,
Zhengyang Geng,
Houwen Peng,
Han Hu,
Shi-min Hu
|
|
|
 |
|
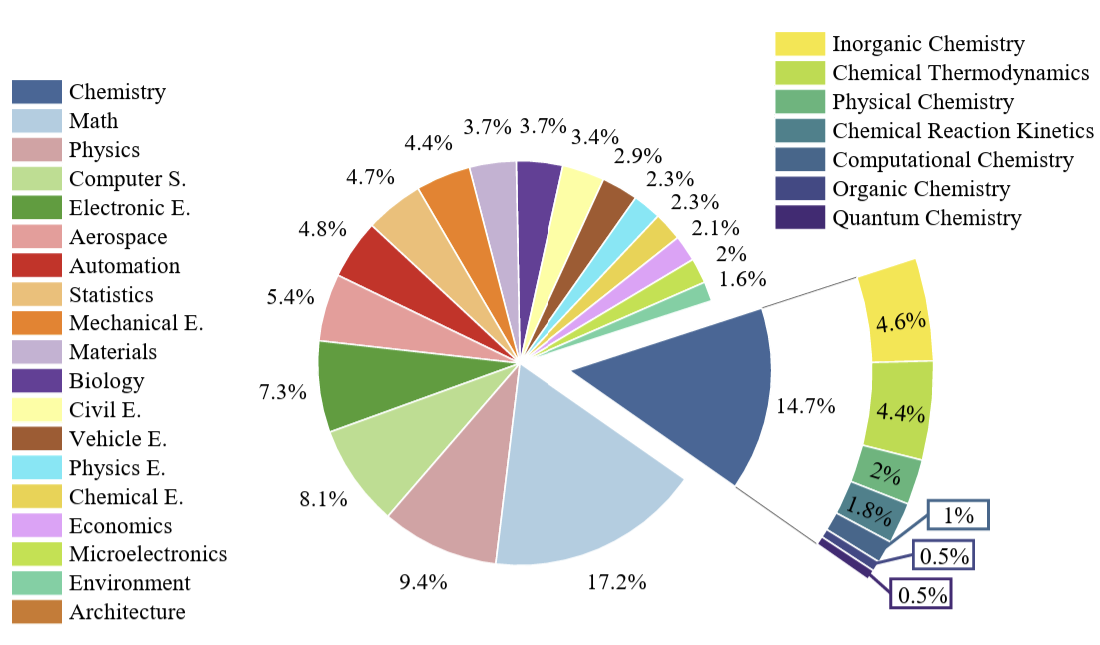
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
Meng-Hao Guo,
Jiajun Xu,
Yi Zhang,
Jiaxi Song,
Haoyang Peng,
Yi-Xuan Deng,
Xinzhi Dong,
Kiyohiro Nakayama,
Zhengyang Geng,
Chen Wang,
Bolin Ni,
Yongming Rao,
Houwen Peng,
Han Hu,
Gordon Wetzstein,
Shi-min Hu
|
|
|
 |
|
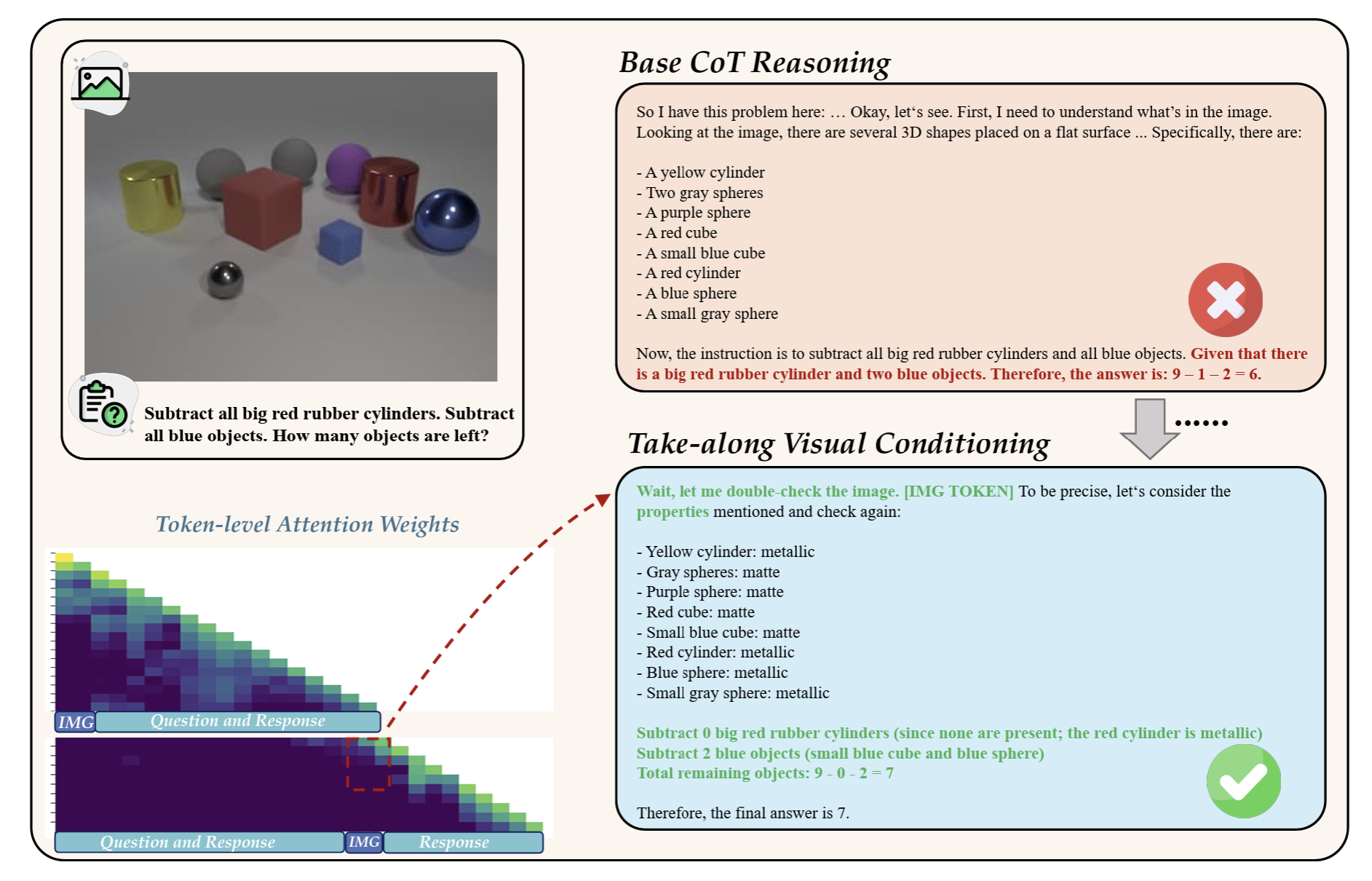
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Hai-Long Sun,
Zhun Sun,
Houwen Peng,
Han-Jia Ye
|
|
|
 |
|
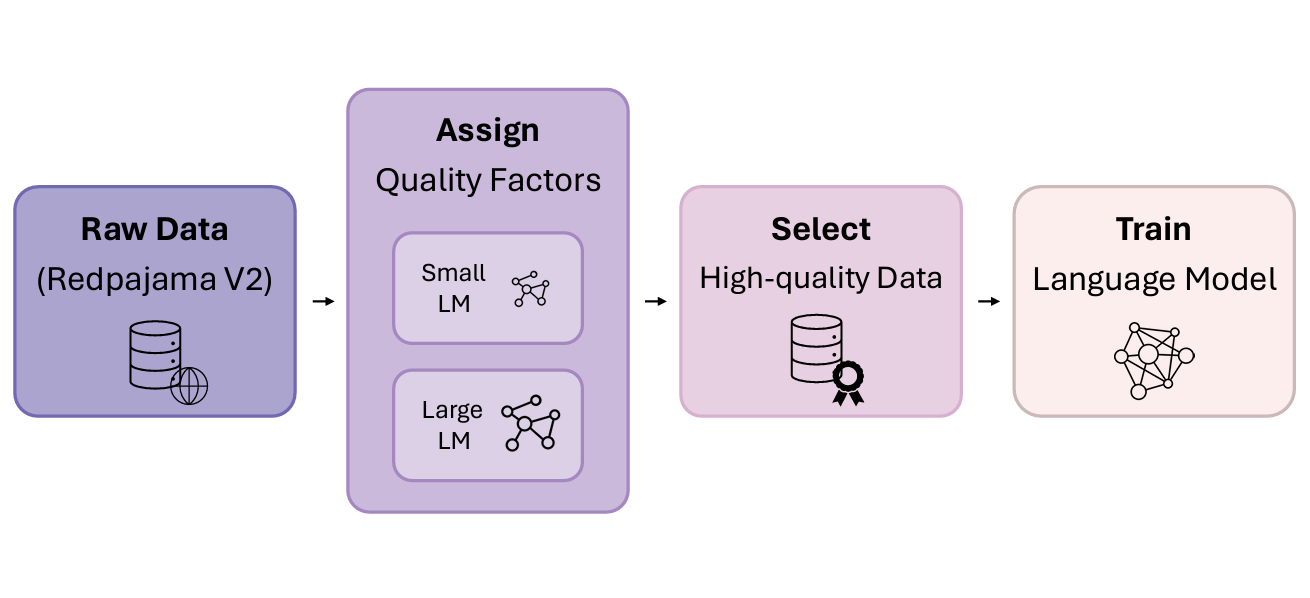
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
|
|
|
 |
|
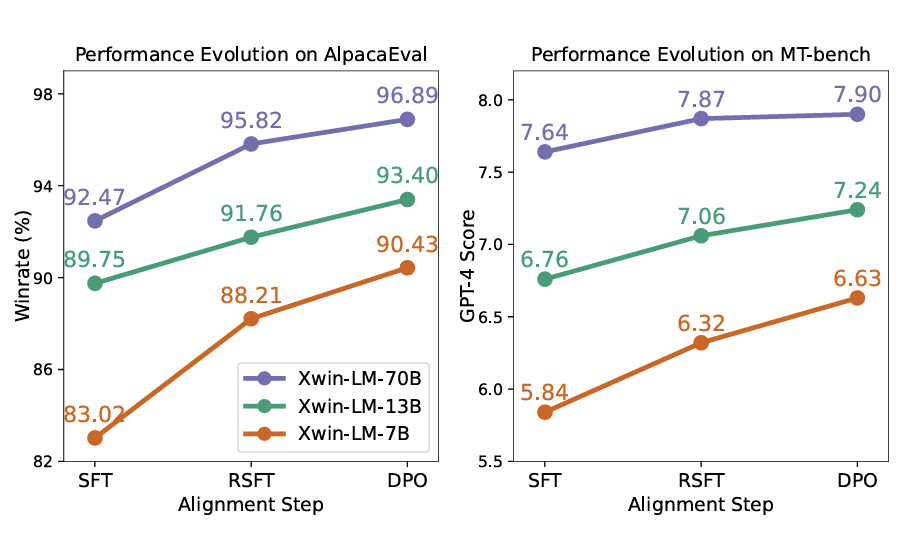
Xwin-LM: Strong and Scalable Alignment Practice for LLMs
|
|
|
 |
|
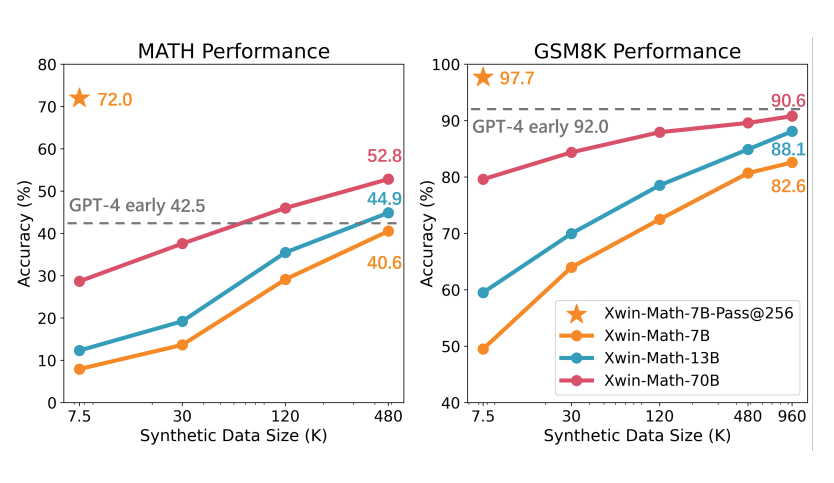
Common 7B Language Models Already Possess Strong Math Capabilities
|
|
|
 |
|
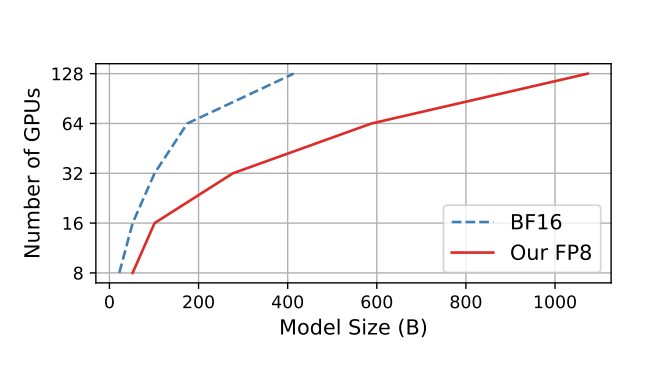
FP8-LM: Training FP8 Large Language Models
Houwen Peng,
Kan Wu,
Yixuan Wei,
Guoshuai Zhao,
Yuxiang Yang,
Ze Liu,
Yifan Xiong,
Ziyue Yang,
Bolin Ni,
Jingcheng Hu,
Ruihang Li,
Miaosen Zhang,
Chen Li,
Jia Ning,
Ruizhe Wang,
Zheng Zhang,
Shuguang Liu,
Han Hu,
Peng Cheng
|
|
|
 |
|
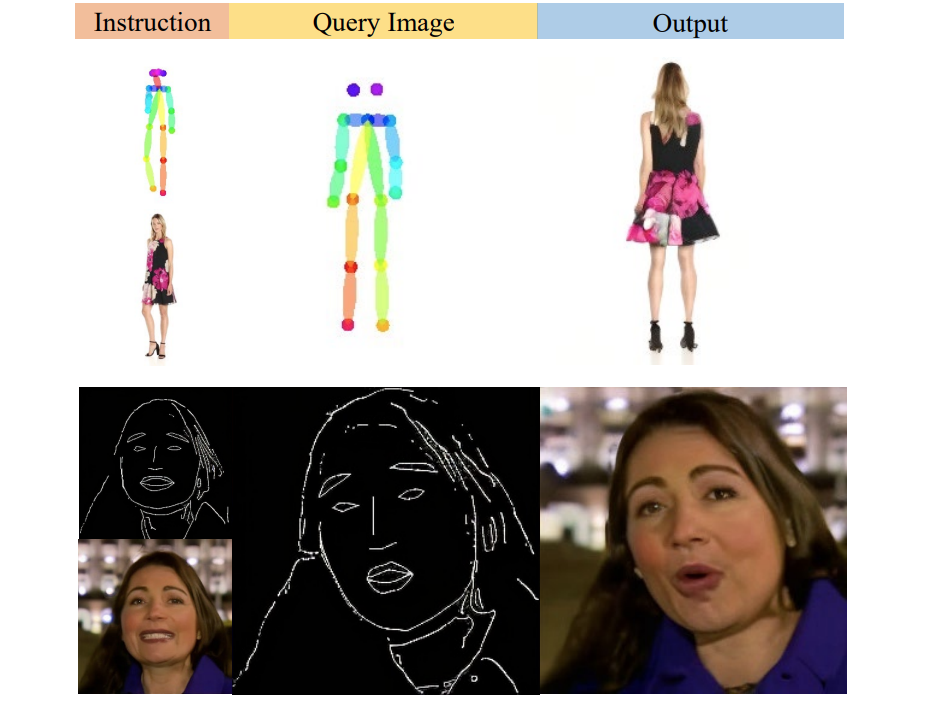
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation
|
|
|
 |
|
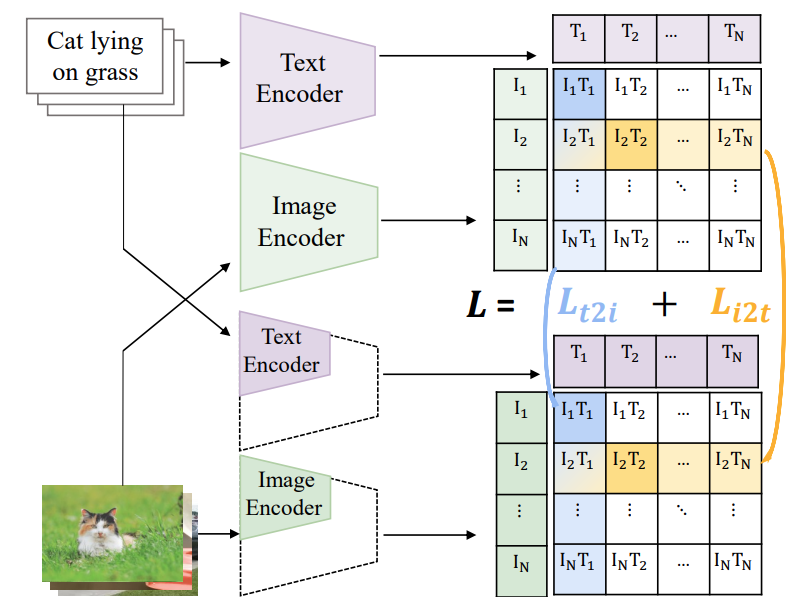
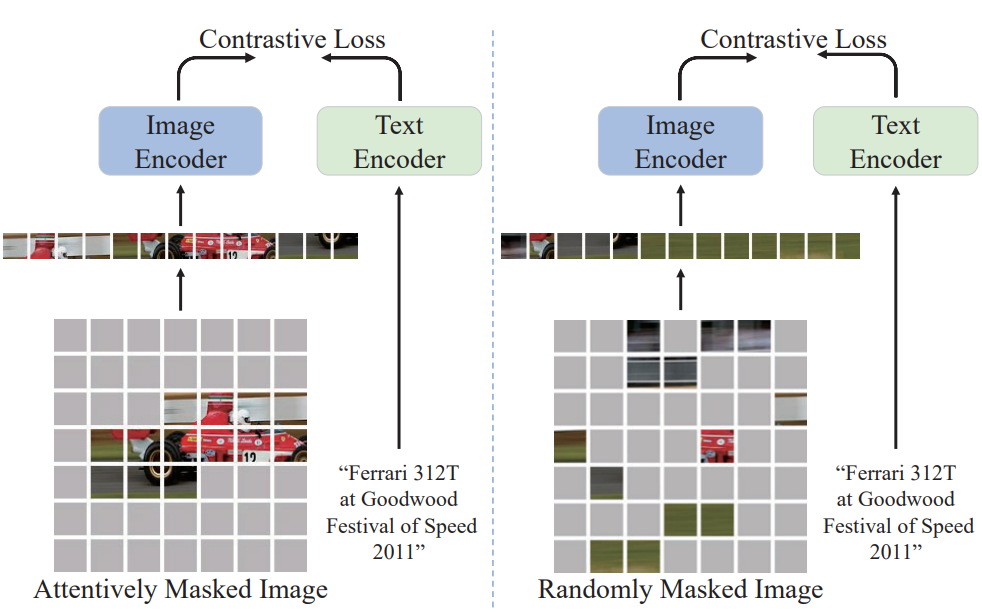
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Kan Wu,
Houwen Peng*,
Zhenghong Zhou,
Bin Xiao,
Mengchen Liu,
Lu Yuan,
Hong Xuan,
Zhenghong Zhou,
Xi Chen,
Xinggang Wang,
Hongyang Chao,
Han Hu
|
|
|
 |
|
 |
|
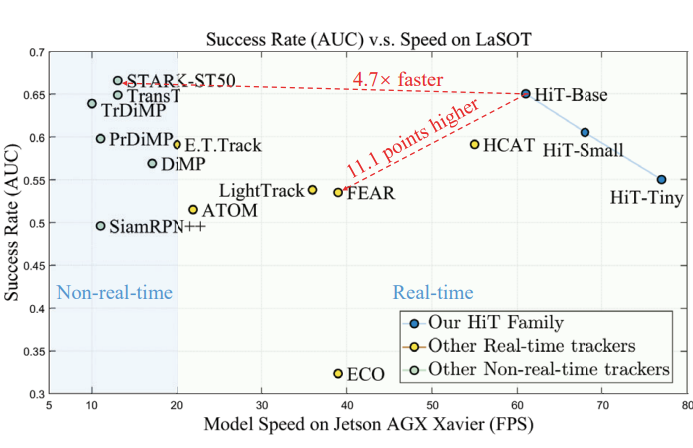
Exploring Lightweight Hierarchical Vision Transformers for Efficient Visual Tracking
|
|
|
 |
|
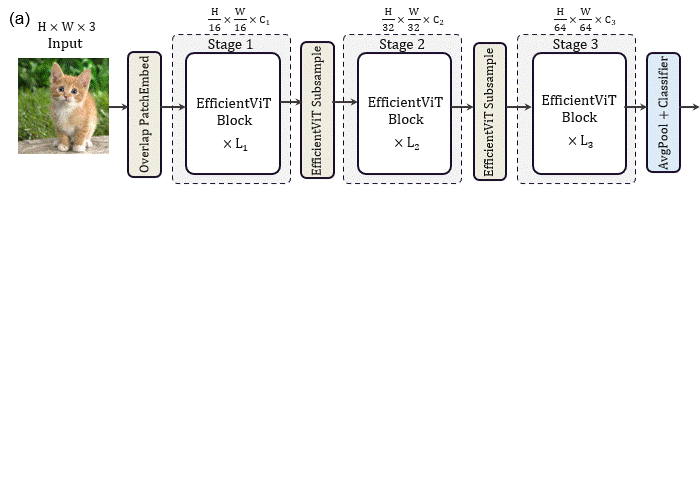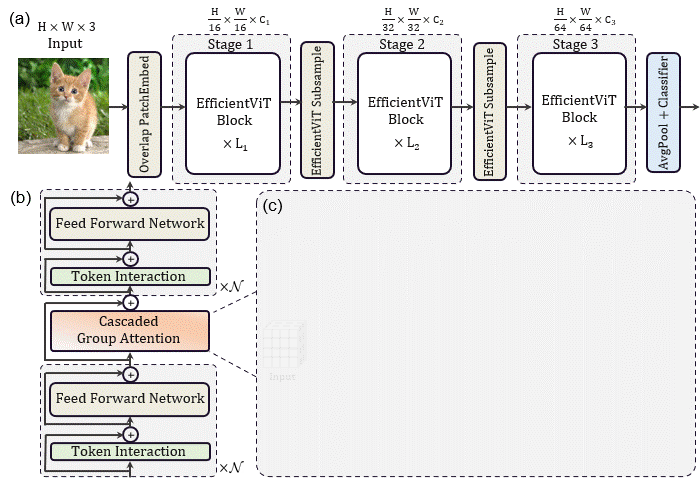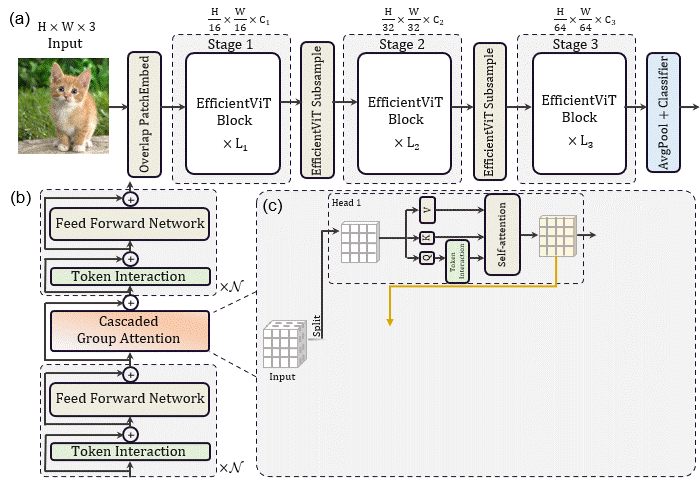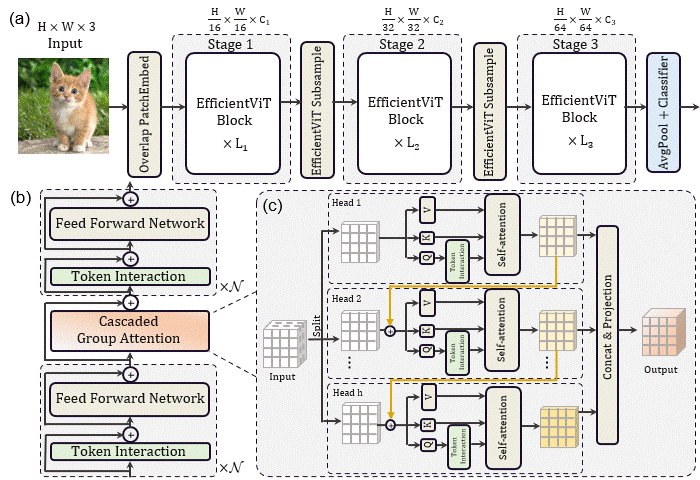
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
|
|
|
 |
|
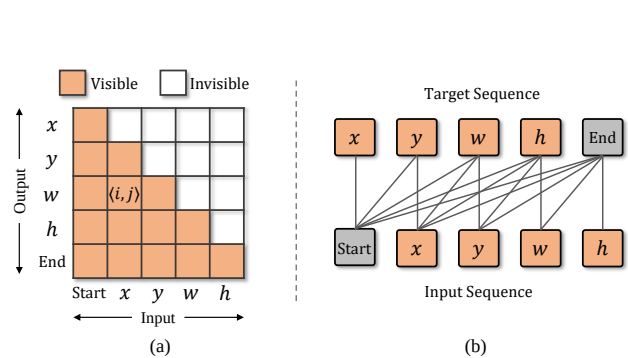
SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
|
|
|
 |
|
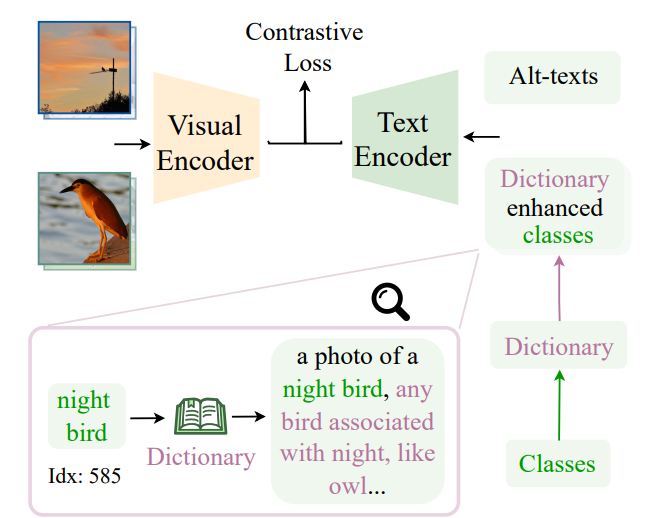
iCLIP: Bridging Image Classification and Contrastive Language-Image Pre-Training for Visual Recognition
|
|
|
 |
|
PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
|
|
|
 |
|
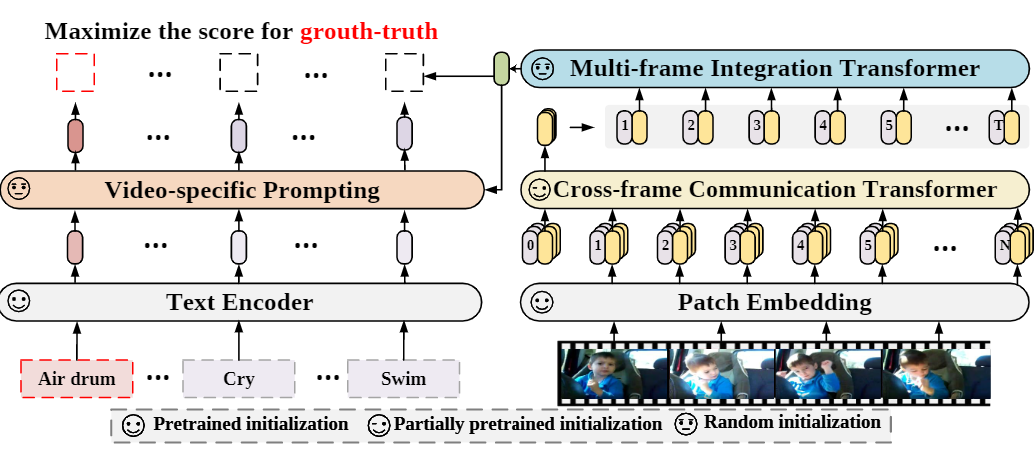
Expanding Language-Image Pretrained Models for General Video Recognition
|
|
|
 |
|
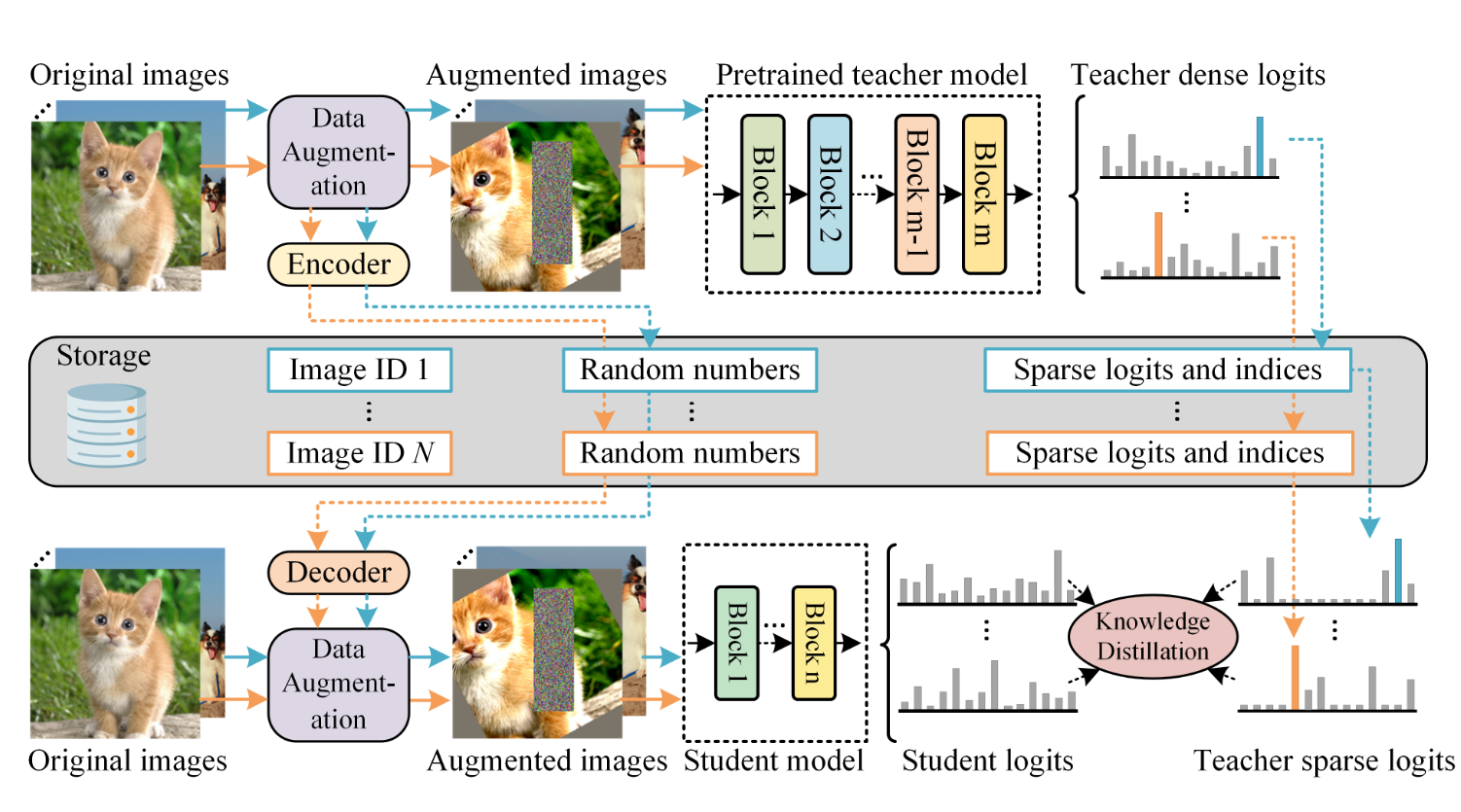
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
|
|
|
 |
|
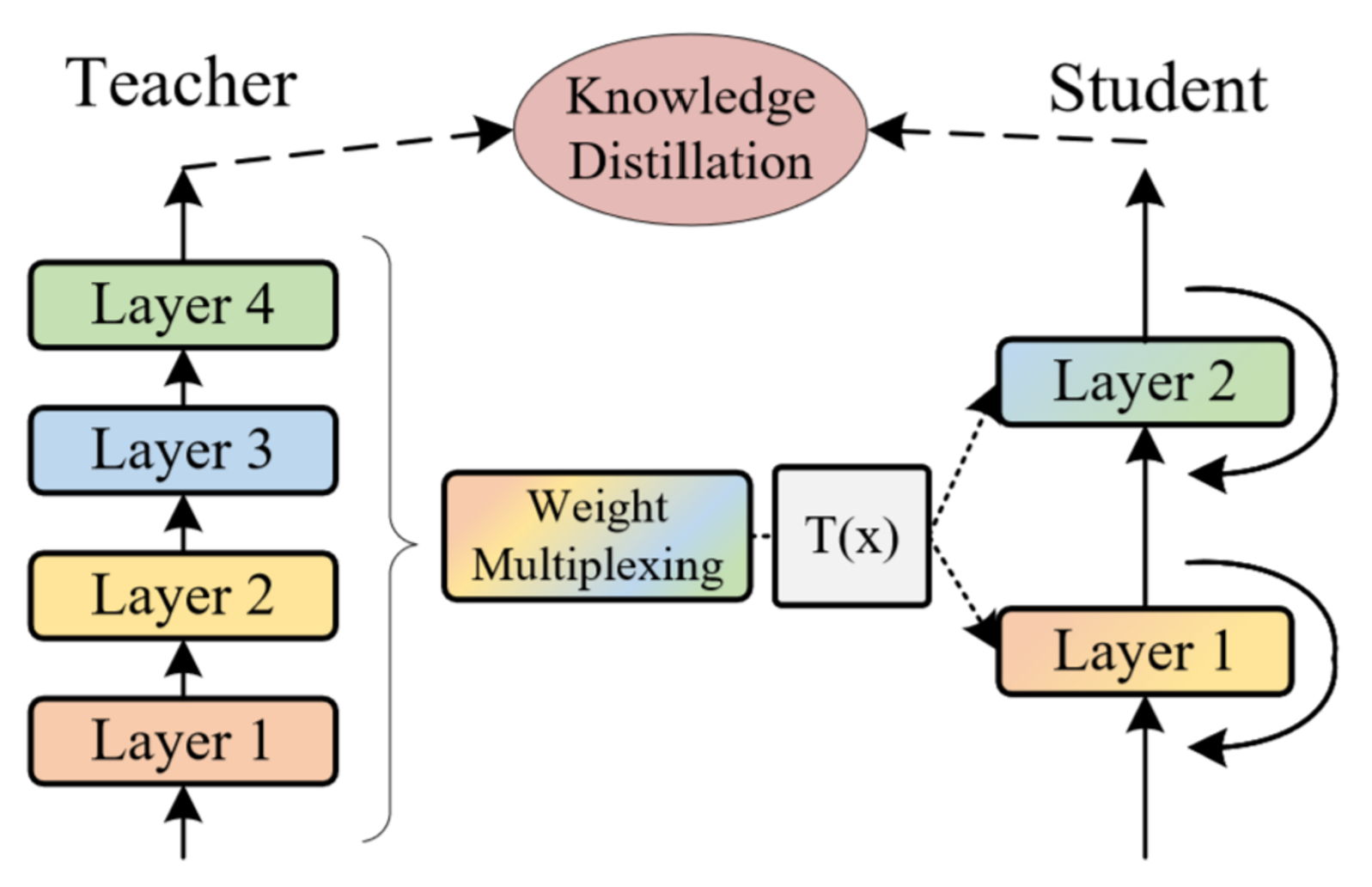
MiniViT: Compressing Vision Transformers with Weight Multiplexing
|
|
|
 |
|
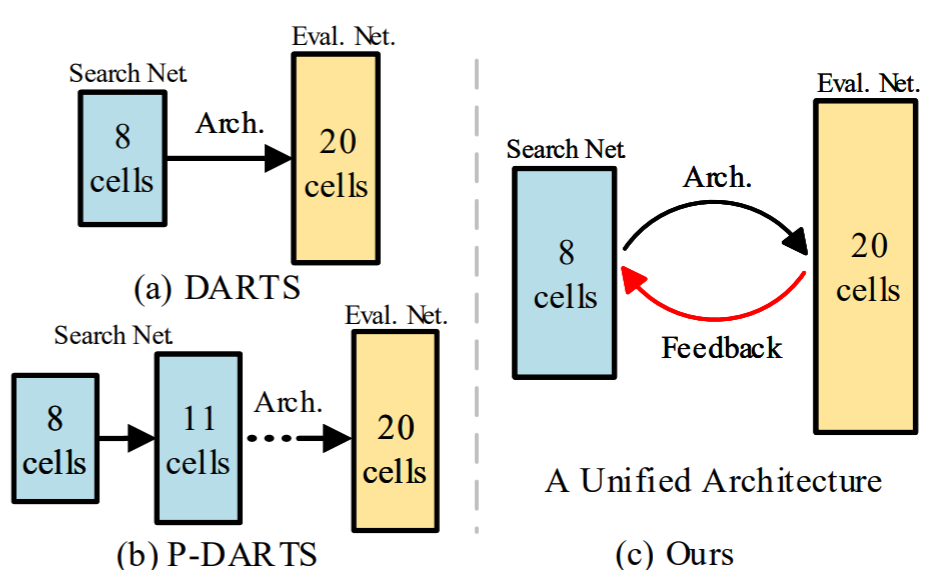
Cyclic Differentiable Architecture Search
|
|
|
 |
|
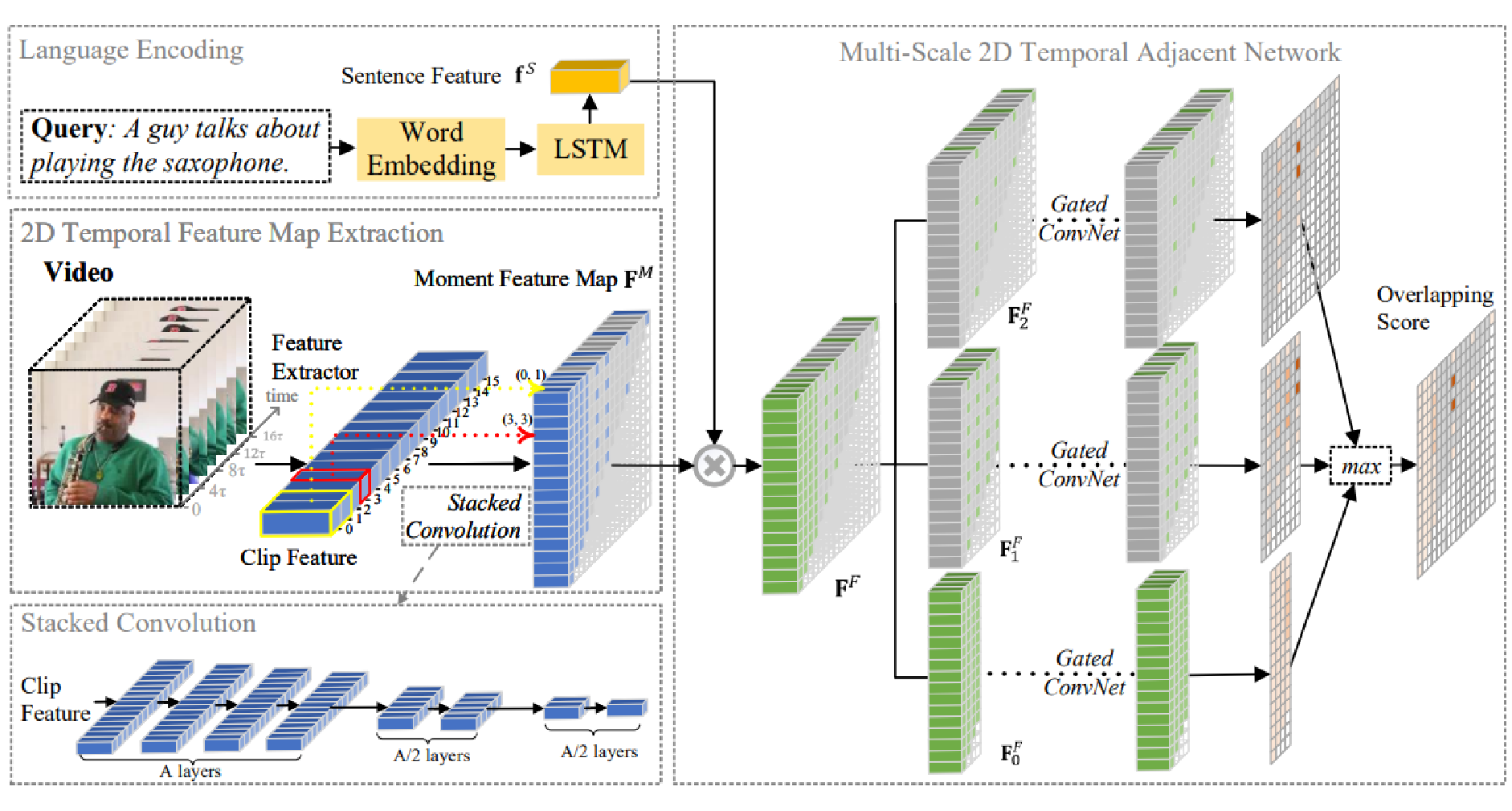
Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
|
|
|
 |
|
AutoFormerV2: Searching the Search Space of Vision Transformer
|
|
|
 |
|
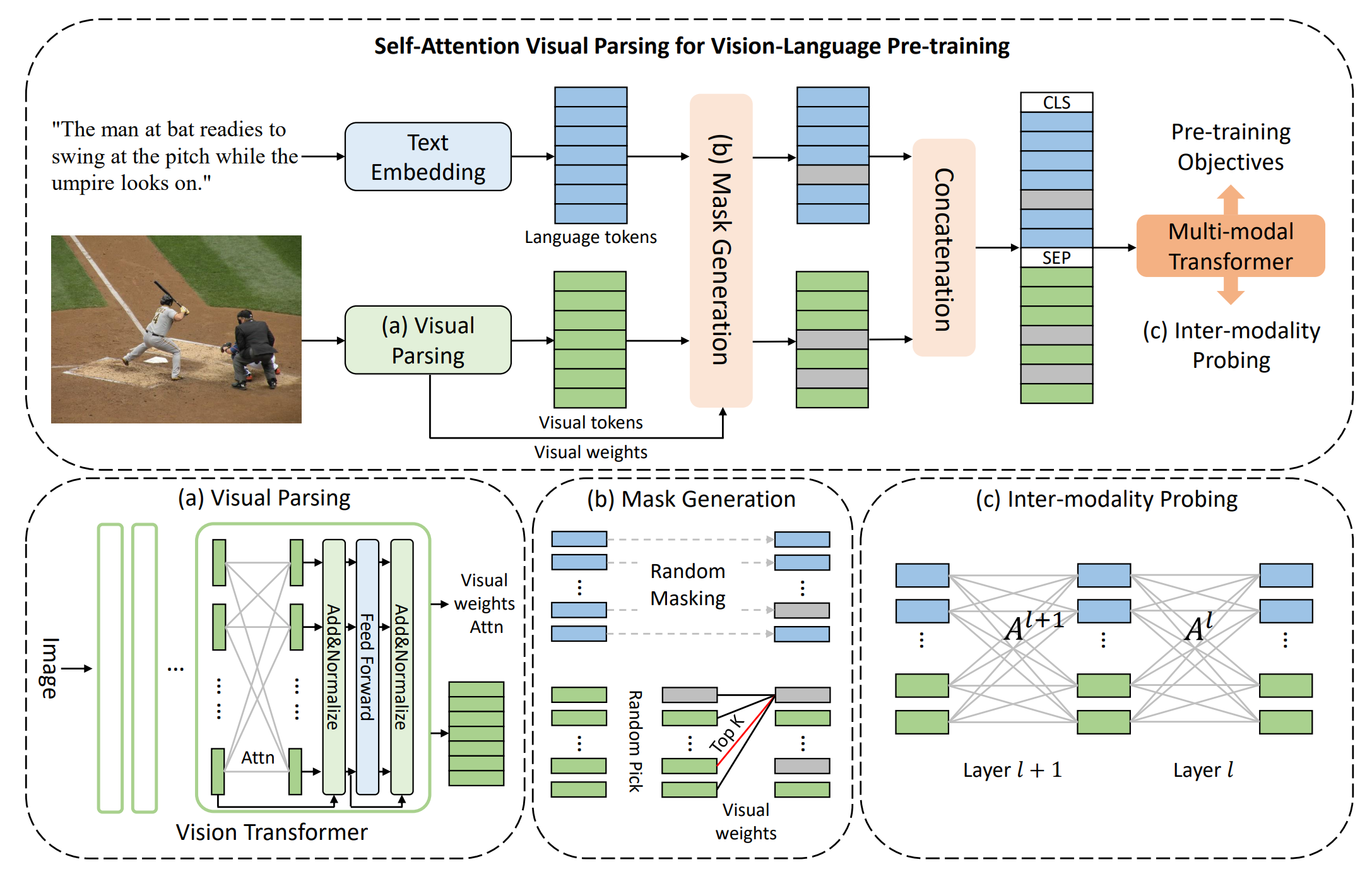
Probing Inter-modality: Visual Parsing with Self-Attention for Vision-and-Language Pre-training
|
|
|
 |
|
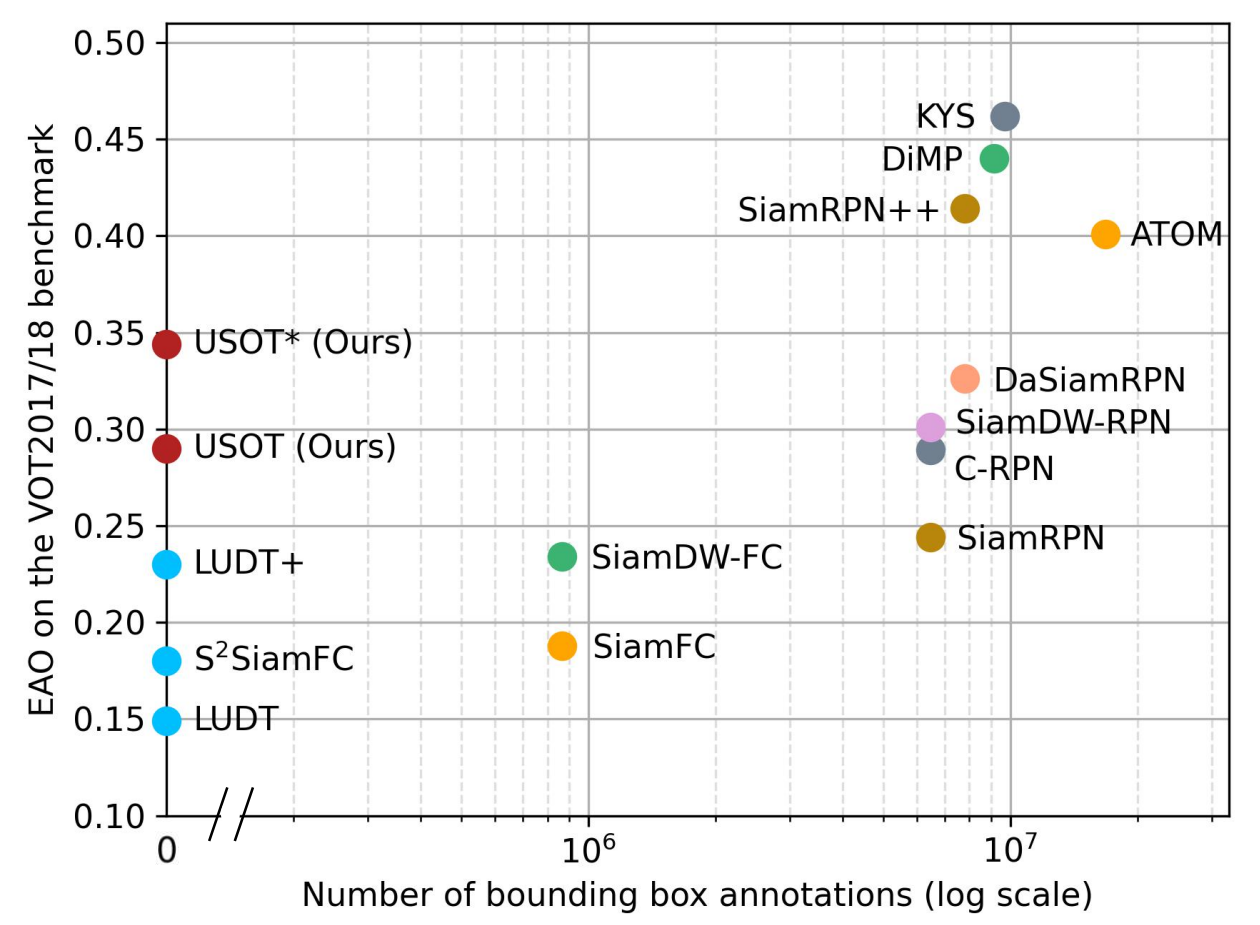
Learning to Track Objects from Unlabled Videos
|
|
|
 |
|
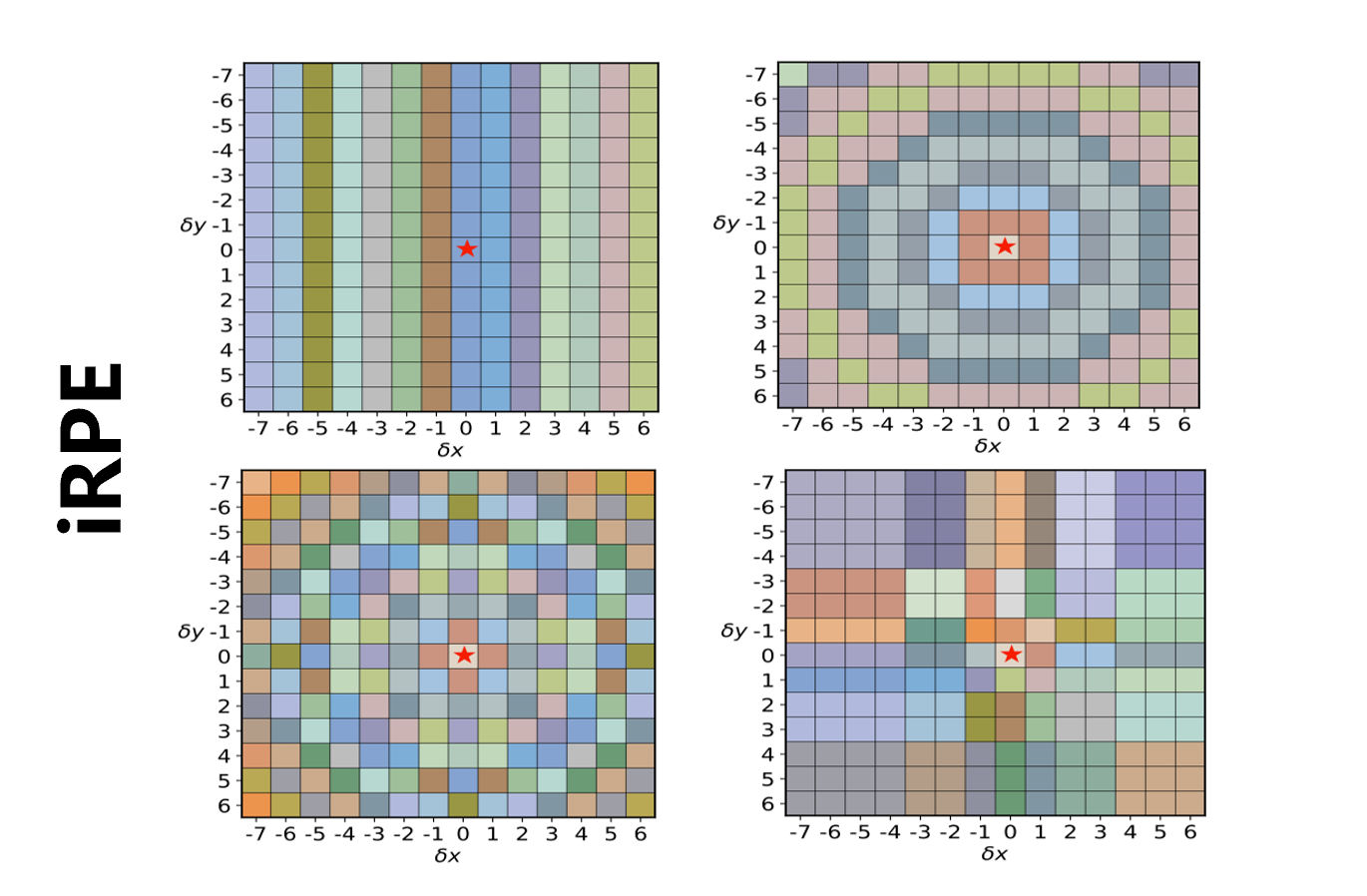
Rethinking and Improving Relative Position Encoding for Vision Transformer
|
|
|
 |
|
AutoFormer: Searching Transformers for Visual Recognition
|
|
|
 |
|
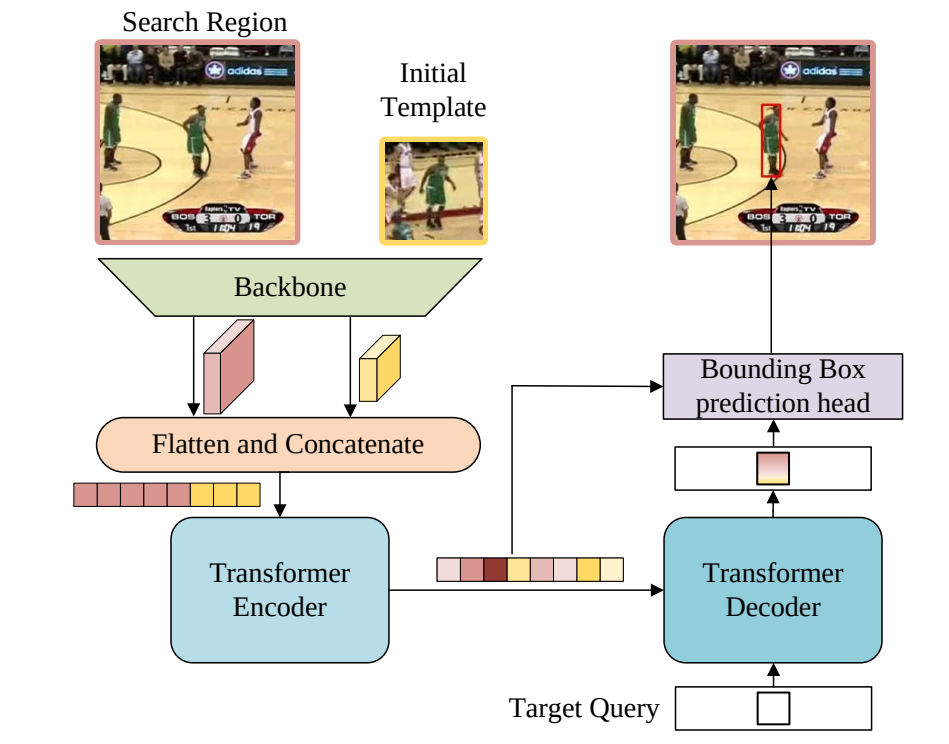
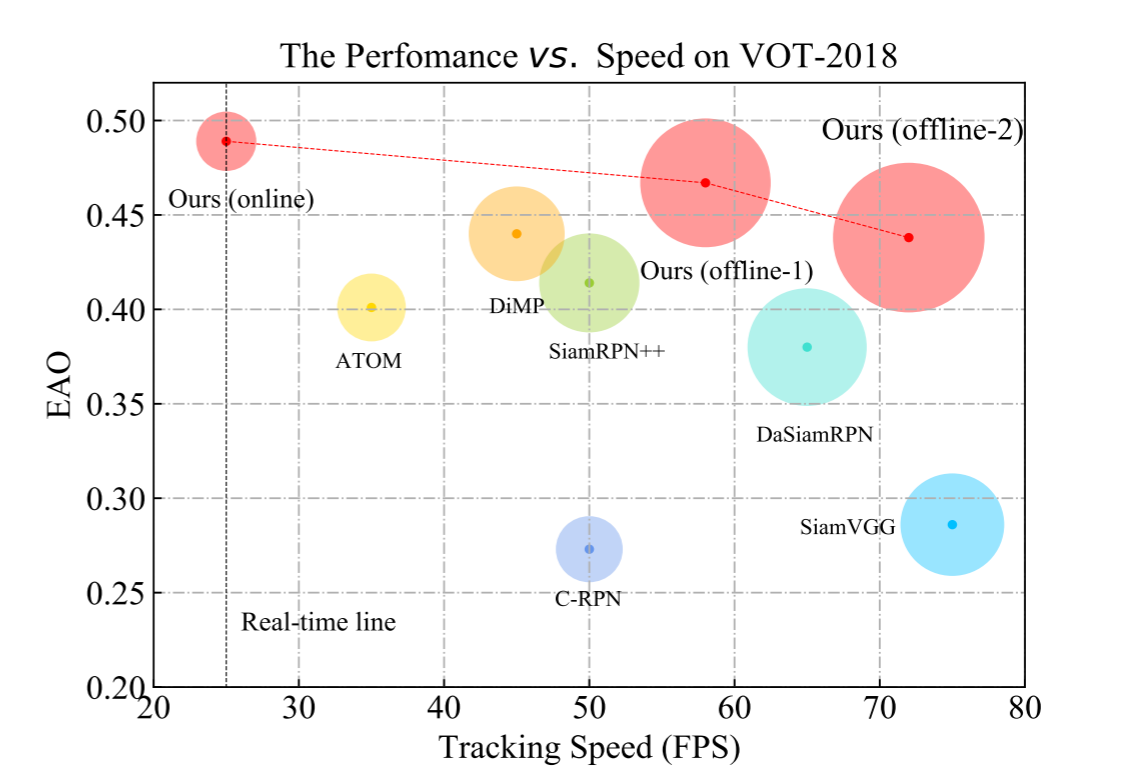
Learning Spatio-Temporal Transformer for Visual Tracking
|
|
|
 |
|
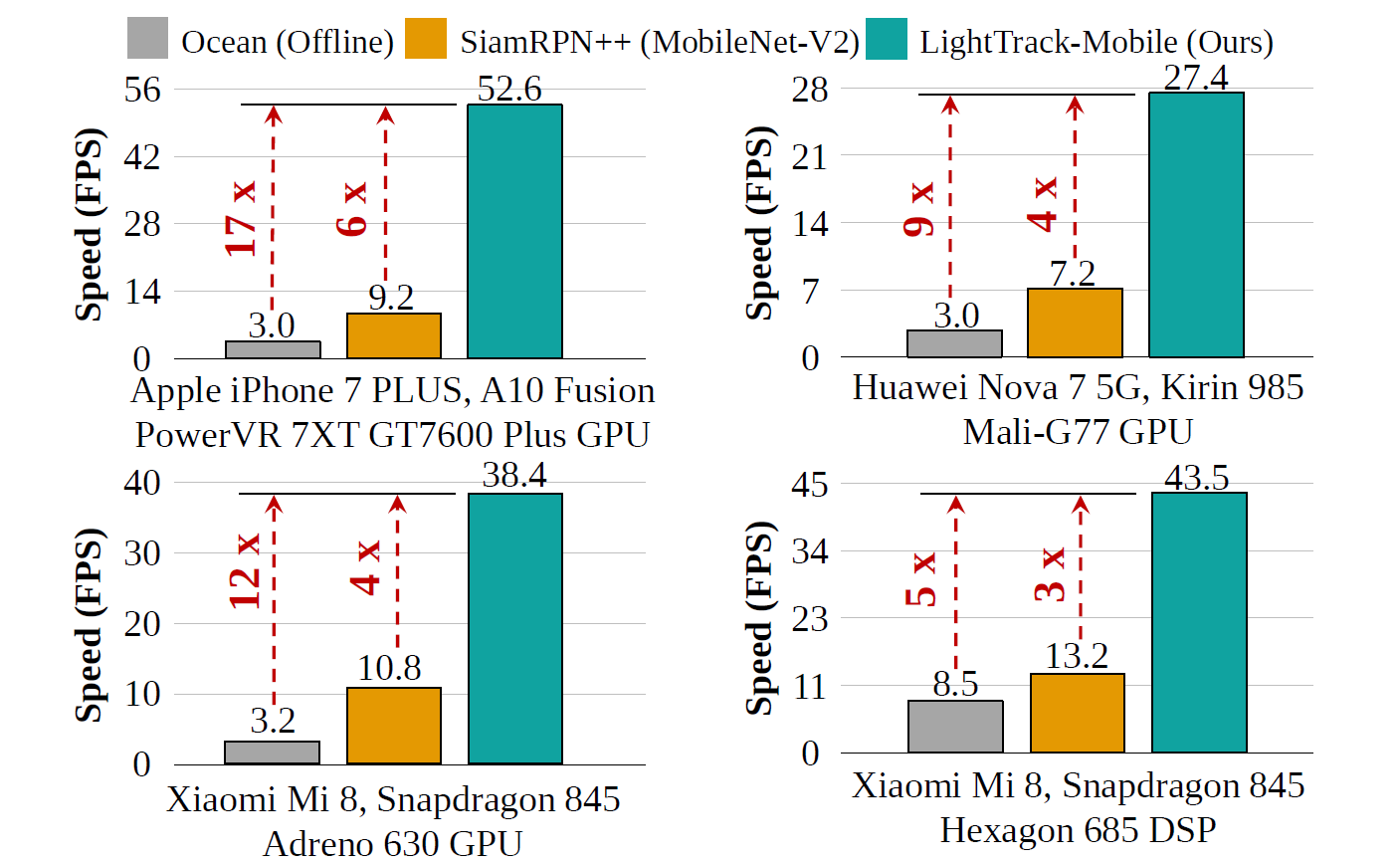
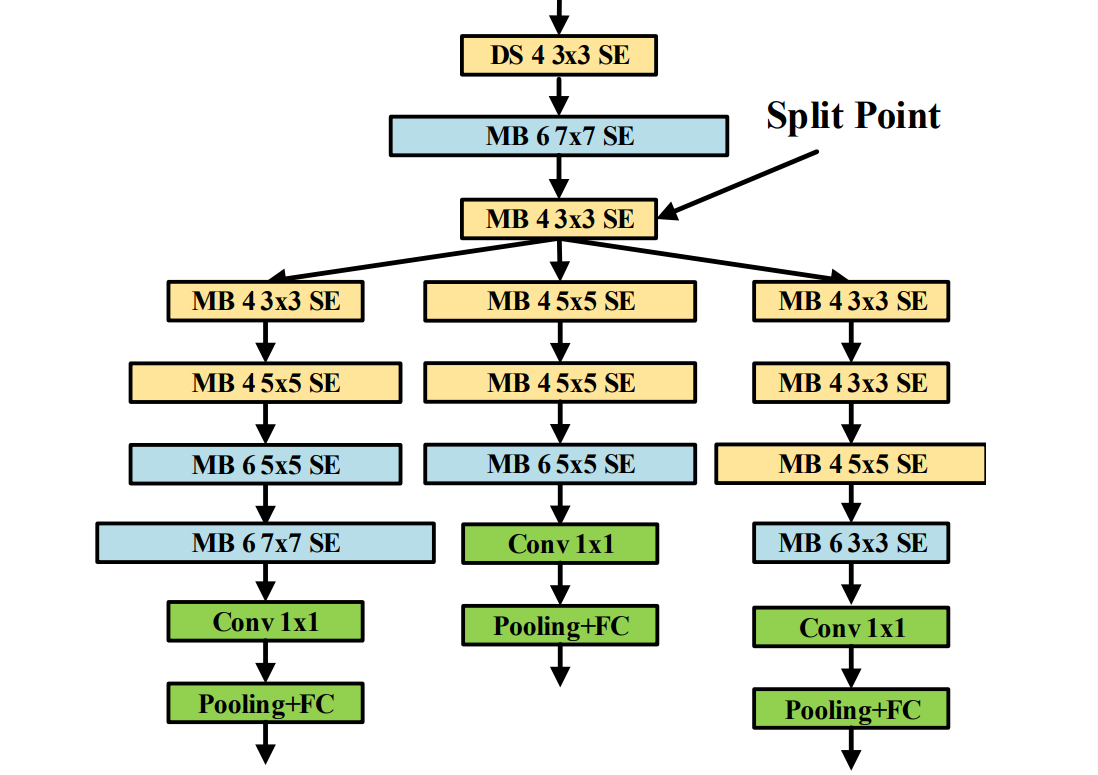
LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
|
|
|
 |
|
One-Shot Neural Ensemble Architecture Search by Diversity-Guided Search Space Shrinking
|
|
|
 |
|
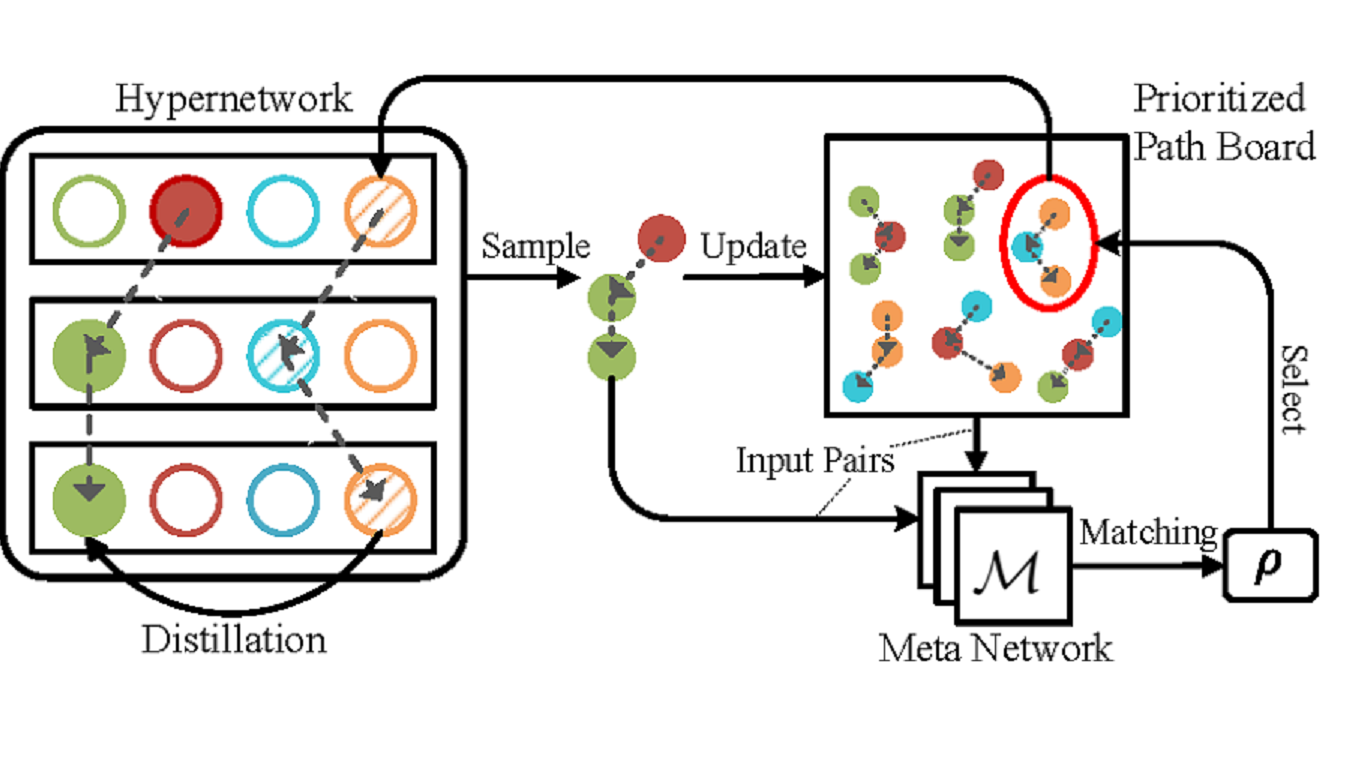
Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search
|
|
|
 |
|
Ocean: Object-aware Anchor-free Tracking
|
|
|
 |
|
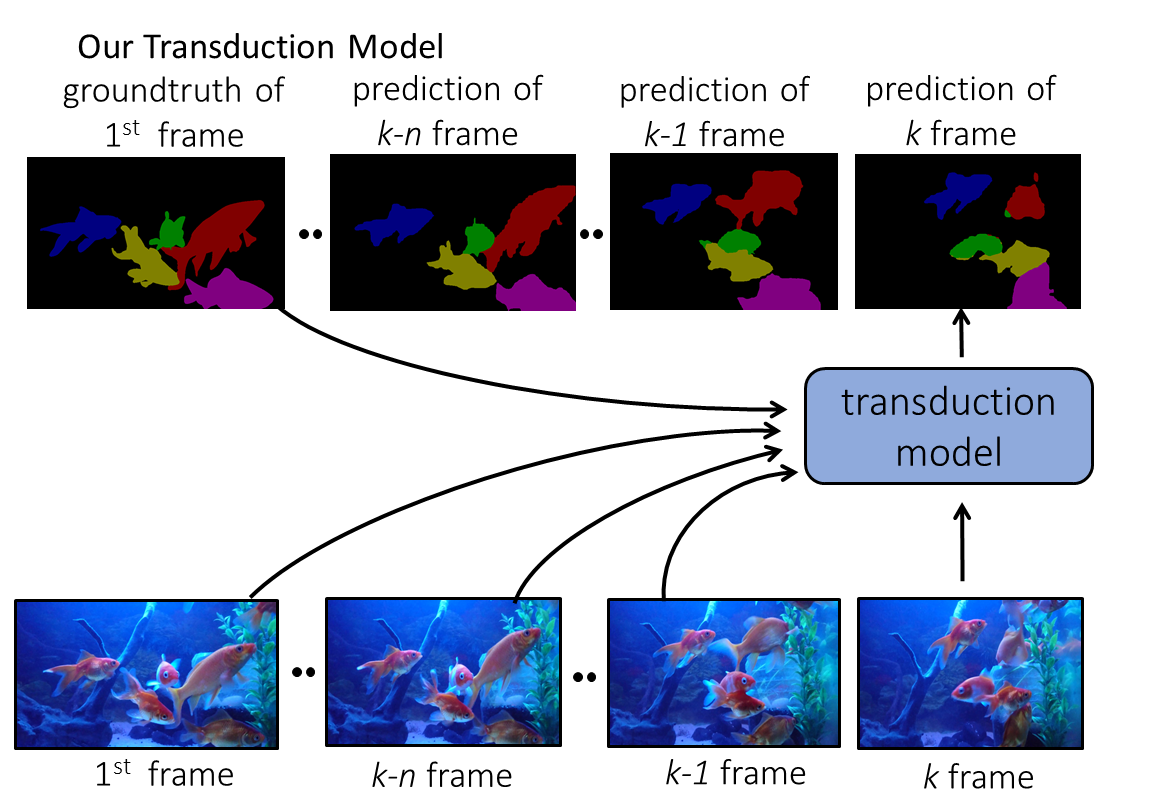
A Transductive Approach for Semi-Supervised Video Object Segmentation
|
|
|
 |
|
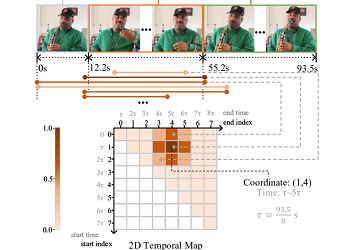
Learning 2D Temporal Localization Networks for Moment Localization with Natural Language
|
|
|
 |
|
Deeper and Wider Siamese Networks for Real-time Visual Tracking
|
|
|
 |
|
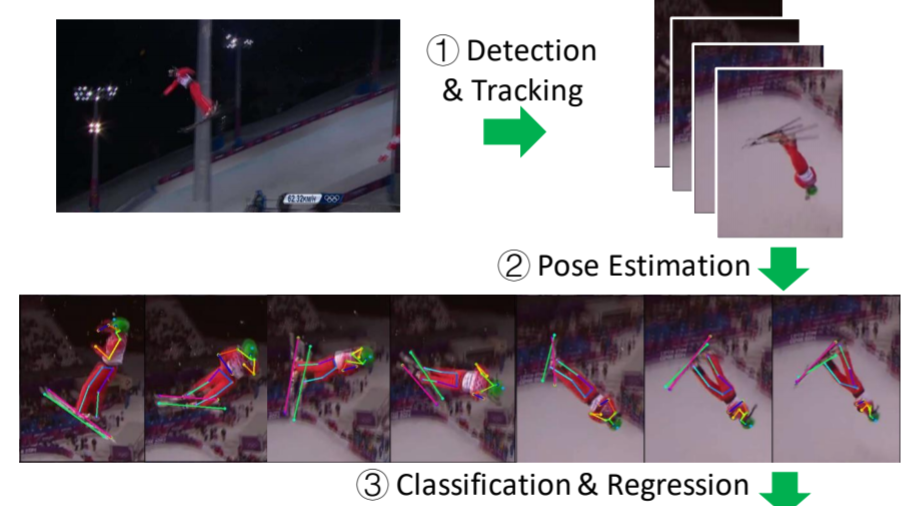
AI Coach: Deep Human Pose Estimation and Analysis for Personalized Athletic Training Assistance
|
|
|
 |
|
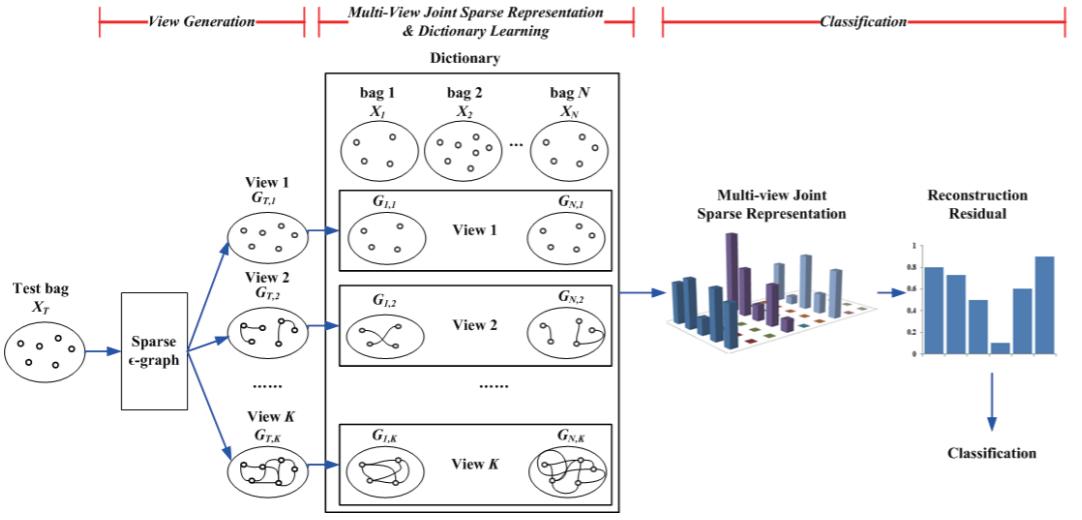
Multi-view Multi-instance Learning based on Joint Sparse Representation and Multi-view Dictionary Learning
|
|
|
 |
|
Illumination Estimation based on Bilayer Sparse Coding
|
|
|
 |
|
Salient Object Detection via Structured Matrix Decomposition
|
|
|
 |
|
Predicting Image Memorability by Multi-view Adaptive Regression
|
|
|
 |
|
RGBD Salient Object Detection: A Benchmark and Algorithms
|
|
|
 |
|
Salient Object Detection via Low-rank and Structured Sparse Matrix Decomposition
|
|
|